
Información del Proyecto
- Categoría: Procesamiento de Lenguaje Natural (NLP)
- Motor de IA: Ollama + LLaMA 3 (Local)
- Backend / Scripting: Python 3.10 + PyPDF2
- Frontend: Next.js 16 + Tailwind CSS
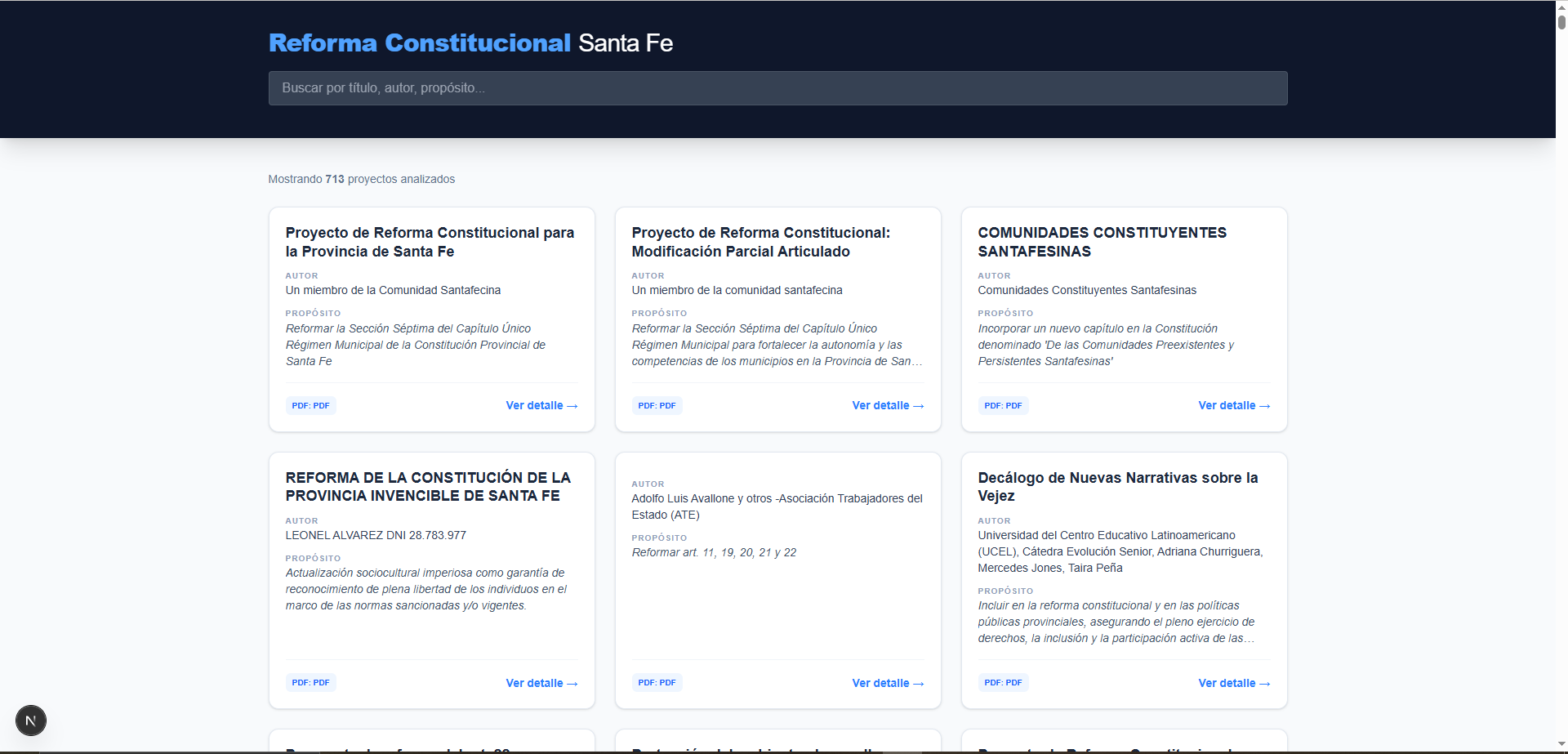
- Data: 695 Proyectos de Reforma (PDF)
- Project URL: www.reforma-santafe.vercel.app
Extracción Inteligente de Datos Legales
Este proyecto nace de la necesidad de analizar de forma masiva los 695 proyectos de reforma para la Constitución de la provincia de Santa Fe. Leer y categorizar manualmente este volumen de documentos técnicos es una tarea inabarcable para un equipo humano en tiempos acotados.
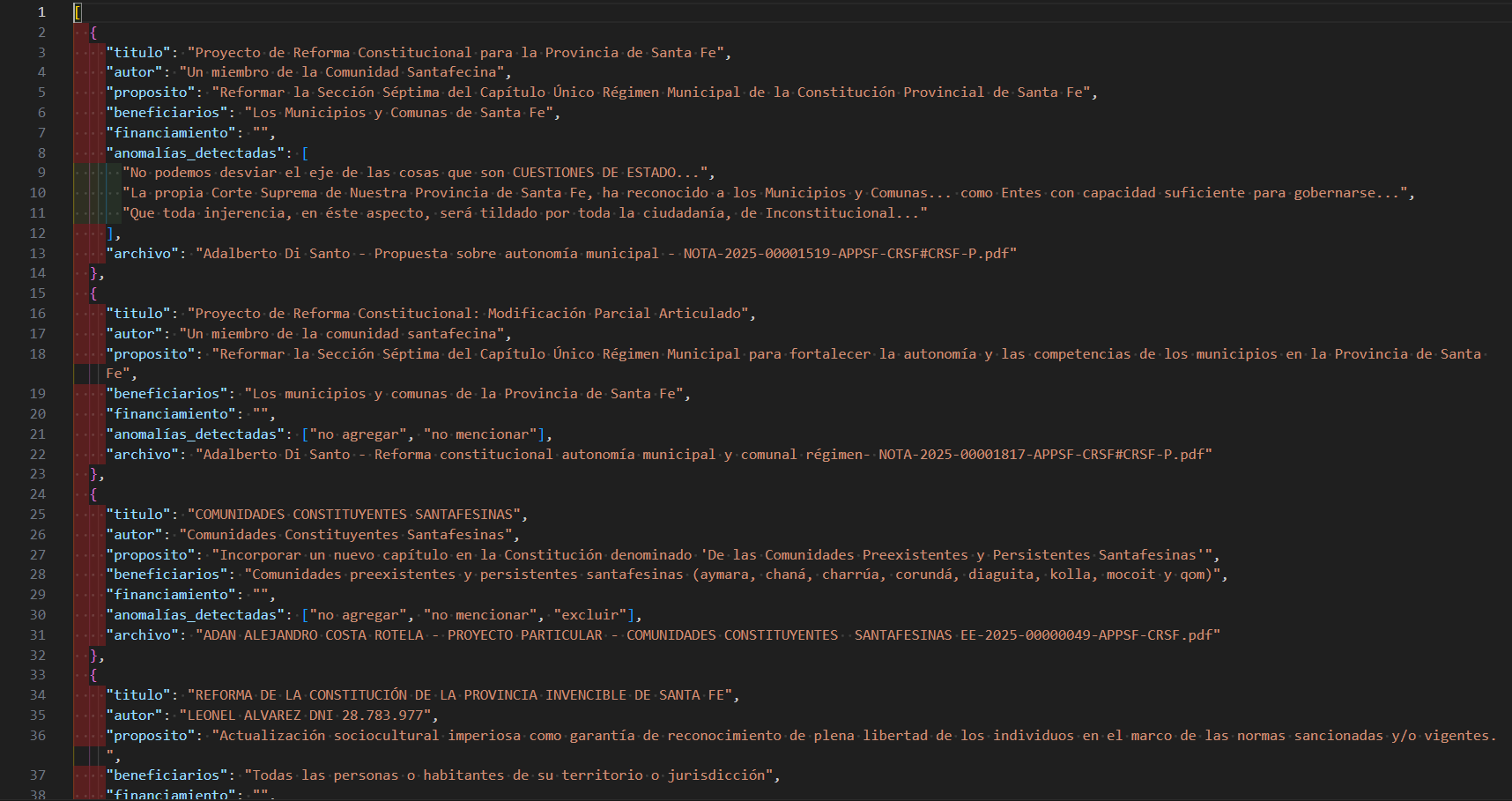
Desarrollé un motor de procesamiento en Python que automatiza el flujo de datos: primero, extrae el texto plano de los archivos PDF; luego, mediante una integración con Ollama (LLaMA 3) ejecutándose de forma local, el sistema realiza un análisis semántico de cada documento.
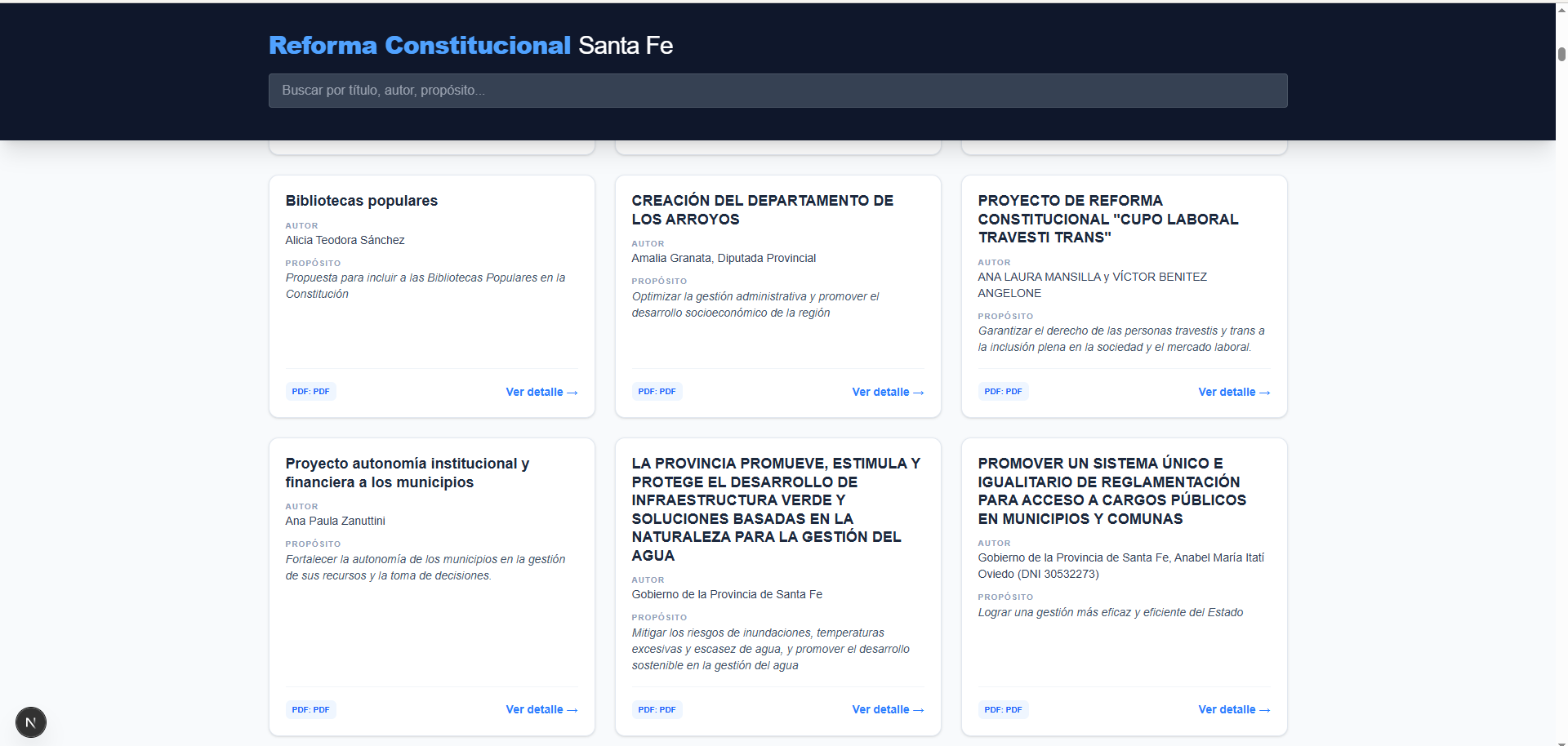
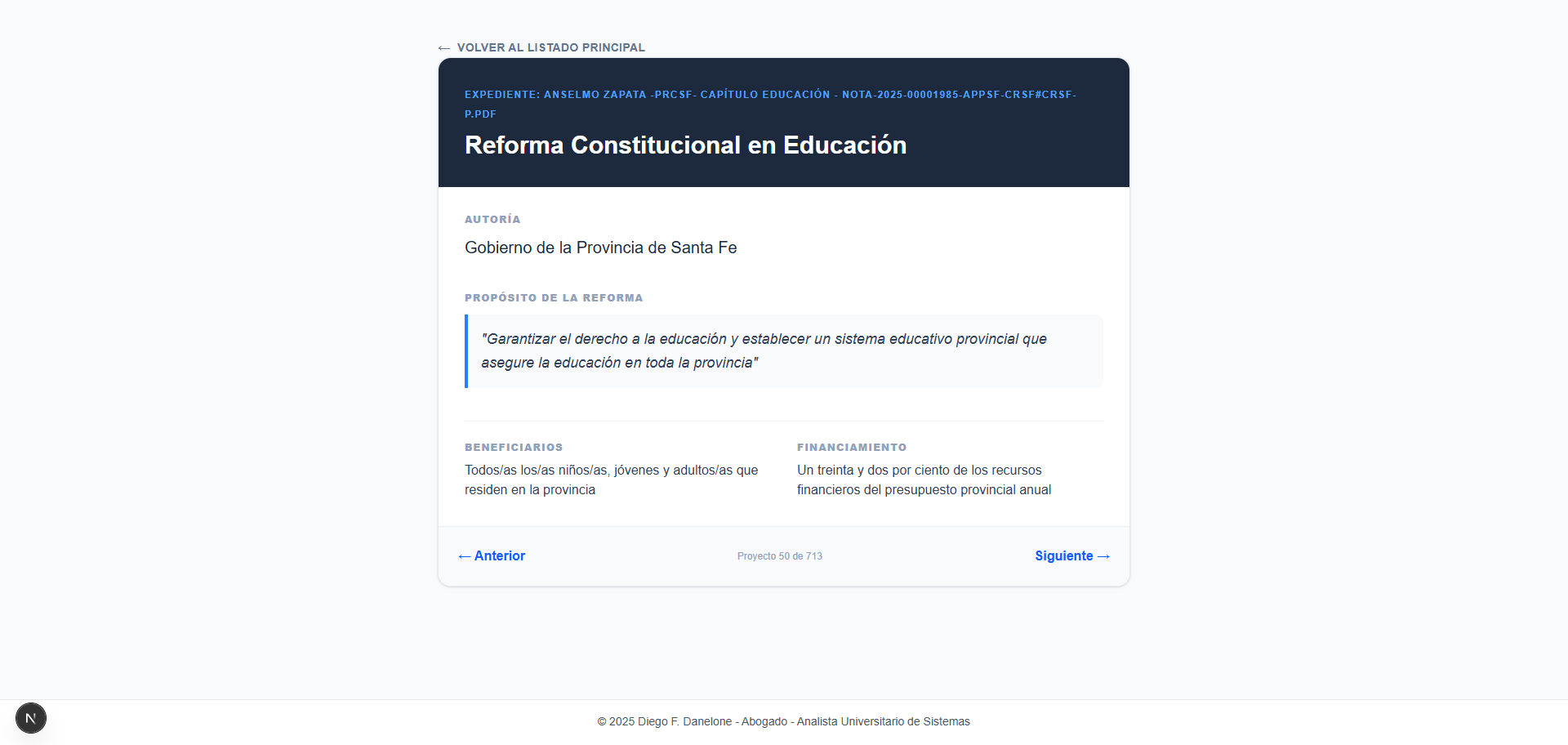
La IA identifica y estructura campos clave como Título, Autor, Propósito, Beneficiarios y Financiamiento, devolviendo un objeto JSON enriquecido. Finalmente, los datos se visualizan en una plataforma web moderna desarrollada con Next.js, permitiendo búsquedas instantáneas y una navegación fluida entre los proyectos analizados.